Top những câu hỏi phỏng vấn tiếng Anh thường gặp với Pandas trong Python

Nếu bạn là một Python Developer, bạn cần chuẩn bị kỹ lưỡng những câu hỏi phỏng vấn thường gặp trong Python. Giúp tăng sự tự tin và tâm lý của bạn khi bước vào cuộc chiến tuyển dụng.
Pandas là một trong những kỹ năng cần thiết nhất cho vai trò liên quan đến dữ liệu. Nhiều chuyên gia dữ liệu hoặc ứng viên đang tìm kiếm những câu hỏi phỏng vấn Pandas được hỏi nhiều nhất để có thể nhận được công việc tốt trong ngành công nghiệp dữ liệu đang phát triển mạnh mẽ. Trong bài viết này, NativeX đã biên soạn Top những câu hỏi phỏng vấn tiếng Anh thường gặp với Pandas trong Python và câu trả lời của họ. Vậy nên, hãy đọc tiếp để khai thác những câu hỏi phỏng vấn Pandas ở mọi cấp độ.
Một số câu hỏi phỏng vấn căn bản về Pandas
Bây giờ chúng ta hãy xem qua một số câu hỏi phỏng vấn cơ bản về Pandas. Bạn là người phỏng vấn có thể bắt đầu bằng những câu hỏi đơn giản này. Mục đích đặt ra những câu hỏi phỏng vấn này sẽ đánh giá sự hiểu biết cơ bản của bạn về Pandas và kỹ năng lập trình Python.
Pandas trong Python là gì?

Pandas là một thư viện Python mã nguồn mở với những phương pháp mạnh mẽ và tích hợp sẵn để hiệu quả làm sạch, phân tích và thao tác tập dữ liệu. Được phát triển bởi Wes McKinney vào năm 2008, gói công cụ mạnh mẽ này dễ dàng tích hợp với nhiều mô-đun khoa học dữ liệu khác trong Python.
Pandas được xây dựng trên nền thư viện NumPy, tức là các cấu trúc dữ liệu Series và DataFrame của nó là phiên bản nâng cấp của mảng NumPy.
Làm cách nào để bạn truy cập 6 hàng trên cùng và 7 hàng cuối cùng của Khung dữ liệu Pandas?
Phương thức head() trong Pandas được sử dụng để truy cập các hàng đầu tiên của DataFrame, và phương thức tail() được sử dụng để truy cập các hàng cuối cùng.
- ✓ Để truy cập 6 hàng đầu tiên: dataframe_name.head(6)
- ✓ Để truy cập 7 hàng cuối cùng: dataframe_name.tail(7)
Tại sao DataFrame.shape không có dấu ngoặc đơn?
Trong Pandas, shape là một thuộc tính và không phải là một phương thức. Do đó, bạn nên truy cập nó mà không cần dấu ngoặc.
Sự khác biệt giữa Series và DataFrame là gì?
- ✓ DataFrame: DataFrame trong Pandas sẽ có định dạng bảng với nhiều hàng và cột, mỗi cột có thể chứa các loại dữ liệu khác nhau.
- ✓ Series: Series là một mảng một chiều có nhãn có thể lưu trữ bất kỳ loại dữ liệu nào, nhưng tất cả các giá trị của nó phải thuộc cùng một loại dữ liệu. Cấu trúc dữ liệu Series giống như một cột duy nhất của DataFrame.
Cấu trúc dữ liệu Series tiêu thụ ít bộ nhớ hơn so với DataFrame. Do đó, một số nhiệm vụ biến đổi dữ liệu có thể thực hiện nhanh chóng trên nó.
Tuy nhiên, DataFrame có thể lưu trữ bộ dữ liệu lớn và phức tạp, trong khi Series chỉ có thể xử lý dữ liệu đồng nhóm. Do đó, tập hợp các hoạt động bạn có thể thực hiện trên DataFrame đáng kể nhiều hơn so với cấu trúc dữ liệu Series.
Index trong Pandas là gì?
Index là một chuỗi nhãn có thể định danh duy nhất từng hàng của DataFrame. Index có thể là bất kỳ kiểu dữ liệu nào như: Số nguyên, chuỗi, hash, v.v.
df.query( ‘ Name == “John” or Marks > 90 ‘ )
print (new_df)
-> df.index in ra các hàng indexes hiện tại của DataFrame df.
NativeX – Học tiếng Anh online toàn diện “4 kỹ năng ngôn ngữ” cho người đi làm.
Với mô hình “Lớp Học Nén” độc quyền:
- Tăng hơn 20 lần chạm “điểm kiến thức”, giúp hiểu sâu và nhớ lâu hơn gấp 5 lần.
- Tăng khả năng tiếp thu và tập trung qua các bài học cô đọng 3 – 5 phút.
- Rút ngắn gần 400 giờ học lý thuyết, tăng hơn 200 giờ thực hành.
- Hơn 10.000 hoạt động cải thiện 4 kỹ năng ngoại ngữ theo giáo trình chuẩn Quốc tế từ National Geographic Learning và Macmillan Education.

Các câu hỏi phỏng vấn về Pandas trình độ trung cấp
Những câu hỏi phỏng vấn này sẽ khó khăn hơn một chút, và bạn khả năng sẽ gặp chúng trong những vị trí yêu cầu kinh nghiệm sử dụng Pandas trước đó.
Multi indexing trong Pandas là gì?
Index trong pandas đặc thù xác định mỗi hàng của DataFrame. Thông thường, chúng ta chọn cột có thể xác định duy nhất từng hàng của DataFrame và thiết lập nó làm Index. Nhưng nếu bạn không có một cột duy nhất có thể thực hiện điều này?
Ví dụ, bạn có các cột “name”, “age”, “address” và “marks” trong một DataFrame. Bất kỳ cột nào ở trên có thể không có giá trị duy nhất cho tất cả các hàng khác nhau và không phù hợp làm Index.
Tuy nhiên, cột “name” và “address” cùng nhau có thể định danh duy nhất mỗi hàng của DataFrame. Vì vậy, bạn có thể đặt cả hai cột làm Index. DataFrame của bạn bây giờ có một Index đa cấp hoặc Index phân cấp.
Giải thích về quá trình reindexing trong Pandas
Reindexing trong pandas cho phép chúng ta tạo một đối tượng DataFrame mới từ DataFrame hiện tại với chỉ mục hàng và nhãn cột đã được cập nhật. Bạn có thể cung cấp một tập hợp các chỉ mục mới cho hàm DataFrame.reindex() và nó sẽ tạo ra một đối tượng DataFrame mới với các chỉ mục được cung cấp và lấy giá trị từ DataFrame thực tế.
Nếu giá trị cho các chỉ mục mới này không có trong DataFrame gốc, hàm sẽ điền vào những vị trí đó bằng giá trị null mặc định. Tuy nhiên, chúng ta có thể thay đổi giá trị mặc định NaN thành bất kỳ giá trị nào chúng ta muốn để điền vào.
Sự khác biệt giữa loc và iloc là gì?
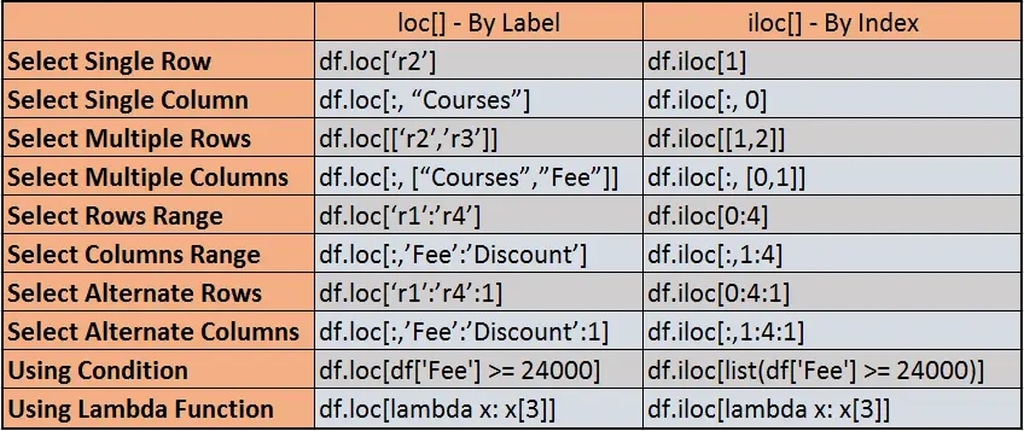
Cả loc và iloc trong pandas đều được sử dụng để chọn các phần tập con của DataFrame. Thực tế, chúng thường được sử dụng rộng rãi để lọc DataFrame dựa trên điều kiện.
Chúng ta nên sử dụng phương thức loc để chọn dữ liệu bằng cách sử dụng các nhãn thực sự của hàng và cột trong khi phương thức iloc được sử dụng để trích xuất dữ liệu dựa trên chỉ số số nguyên của hàng và cột.
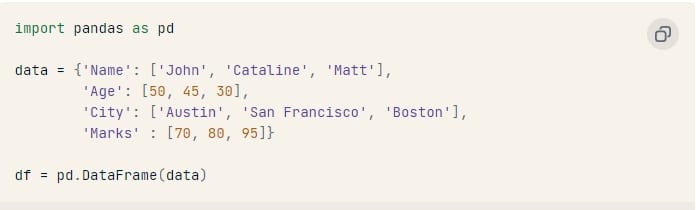
Hiển thị hai cách khác nhau để tạo một DataFrame trong Pandas
Sử dụng từ điển Python:
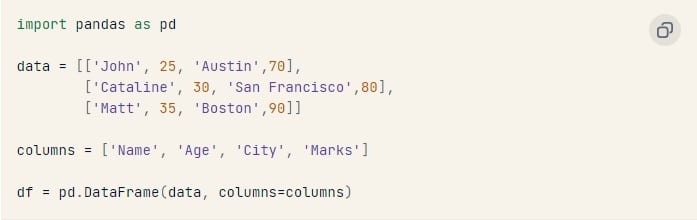
Sử dụng danh sách Python:
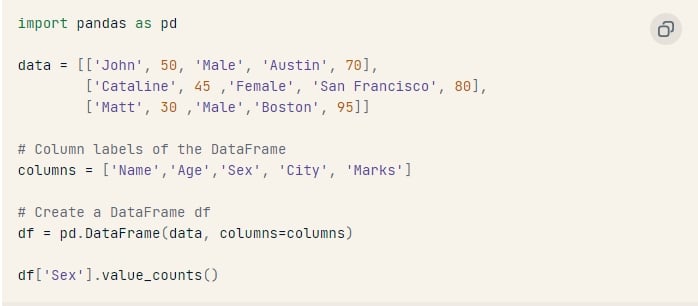
Làm thế nào để lấy số lượng của tất cả các giá trị duy nhất của một cột dạng danh mục trong một DataFrame?
Hàm Series.value_counts() trả về số lần xuất hiện của mỗi giá trị duy nhất trong một chuỗi hoặc một cột.
Ví dụ:
Chúng ta đã tạo một DataFrame df chứa một cột phân loại có tên là ‘Sex’, và chạy hàm value_counts() để xem số lần xuất hiện của mỗi giá trị duy nhất trong cột đó.
Một số câu hỏi phỏng vấn dành cho những người đã có kinh nghiệm
Những bạn đã có nền tảng vững chắc về Pandas và đang xin vào những vị trí cấp cao hơn có thể sẽ gặp phải một số câu hỏi sau:
Làm thế nào để tối ưu hiệu suất khi làm việc với các bộ dữ liệu lớn trong Pandas?
- ✓ Giảm tải dữ liệu: Khi đọc dữ liệu bằng pd.read_csv(), chỉ chọn các cột cần thiết với tham số “usecols” để tránh tải dữ liệu không cần thiết. Thêm vào đó, việc chỉ định tham số “chunksize” chia dữ liệu thành các phần khác nhau và xử lý chúng theo tuần tự.
- ✓ Tránh sử dụng vòng lặp: Vòng lặp và các lần lặp là công việc tốn kém, đặc biệt khi làm việc với các bộ dữ liệu lớn. Thay vào đó, hãy chọn các phép toán vector hóa, vì chúng được áp dụng trên toàn bộ cột một lần, giúp tăng tốc so với việc lặp từng dòng.
- ✓ Sử dụng tổng hợp dữ liệu: Hãy thử tổng hợp dữ liệu và thực hiện các phép toán thống kê vì các phép toán trên dữ liệu đã được tổng hợp thường hiệu quả hơn so với trên toàn bộ bộ dữ liệu.
- ✓ Sử dụng đúng kiểu dữ liệu: Kiểu dữ liệu mặc định trong Pandas không hiệu quả về bộ nhớ. Ví dụ, giá trị nguyên có kiểu dữ liệu mặc định là int64, nhưng nếu giá trị của bạn có thể fit vào int32, việc điều chỉnh kiểu dữ liệu thành int32 có thể tối ưu hóa việc sử dụng bộ nhớ.
- ✓ Xử lý song song: Dask là một API giống Pandas để làm việc với các bộ dữ liệu lớn. Nó sử dụng nhiều quy trình của hệ thống của bạn để thực hiện các nhiệm vụ dữ liệu khác nhau một cách song song.
Sự khác biệt giữa các phương thức Join và Merge trong Pandas là gì?
Join: Kết hợp hai DataFrame dựa trên chỉ số của chúng. Tuy nhiên, có một đối số tùy chọn ‘on’ để xác định rõ liệu bạn muốn kết hợp dựa trên các cột hay không. Theo mặc định, hàm này thực hiện left join.
Cú pháp: df1.join(df2)
Merge: Hàm merge linh hoạt hơn, cho phép bạn xác định các cột mà bạn muốn kết hợp giữa hai DataFrame. Nó thực hiện inner join theo mặc định, nhưng có thể tùy chỉnh để sử dụng các loại join khác nhau như left, right, outer, inner, và cross.
Cú pháp: pd.merge(df1, df2, on=”tên_cột”)
Timedelta là gì?
Timedelta đại diện cho khoảng thời gian, tức là sự khác biệt giữa hai ngày hoặc thời gian, được đo lường bằng đơn vị như ngày, giờ, phút và giây.
Sự khác biệt giữa các phương thức append và concat trong Pandas là gì?
Chúng ta có thể sử dụng phương thức concat để kết hợp các DataFrame theo các hàng hoặc cột. Tương tự, append cũng được sử dụng để kết hợp các DataFrame, nhưng chỉ theo các hàng.
Với hàm concat, bạn có linh hoạt để sửa đổi DataFrame gốc bằng cách sử dụng tham số “inplace”, trong khi hàm append không thể sửa đổi DataFrame thực tế, thay vào đó, nó tạo ra một DataFrame mới với dữ liệu được kết hợp.
NativeX – Học tiếng Anh online toàn diện “4 kỹ năng ngôn ngữ” cho người đi làm.
Với mô hình “Lớp Học Nén” độc quyền:
- Tăng hơn 20 lần chạm “điểm kiến thức”, giúp hiểu sâu và nhớ lâu hơn gấp 5 lần.
- Tăng khả năng tiếp thu và tập trung qua các bài học cô đọng 3 – 5 phút.
- Rút ngắn gần 400 giờ học lý thuyết, tăng hơn 200 giờ thực hành.
- Hơn 10.000 hoạt động cải thiện 4 kỹ năng ngoại ngữ theo giáo trình chuẩn Quốc tế từ National Geographic Learning và Macmillan Education.
Những câu hỏi phỏng vấn lập trình Pandas
Các kỹ năng thực tế cũng quan trọng như kiến thức lý thuyết khi bạn tham gia phỏng vấn công nghệ. Vì vậy đây là một số câu hỏi phỏng vấn về Pandas mà bạn cần biết trước khi đối mặt với người phỏng vấn của bạn.
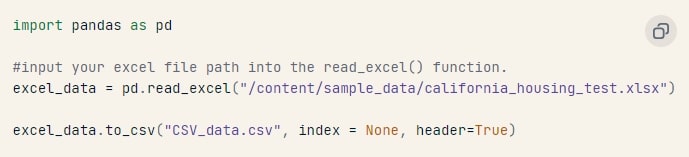
Làm cách nào để đọc tệp Excel sang CSV bằng Pandas ?
Đầu tiên, chúng ta nên sử dụng hàm read_excel() để lấy dữ liệu từ tệp Excel vào một biến. Sau đó, chỉ cần sử dụng hàm to_csv() cho một quá trình chuyển đổi trôi chảy.
Dưới đây là đoạn mã mẫu:
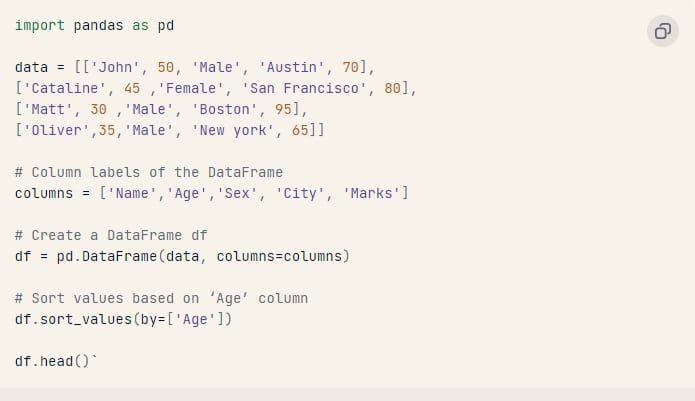
Làm cách nào để sắp xếp DataFrame dựa trên các cột?
Chúng ta có phương thức sort_values() để sắp xếp DataFrame dựa trên một cột hoặc nhiều cột.
Cú pháp: df.sort_values(by=[“tên_cột”])
Ví dụ:
Hiển thị 2 cách lọc dữ liệu khác nhau
Để tạo một DataFrame:

Phương thức 1: Dựa trên điều kiện

Phương thức 2: Sử dụng hàm truy vấn

Làm thế nào để bạn tổng hợp dữ liệu và áp dụng một số hàm tổng hợp như giá trị trung bình hoặc tổng trên dữ liệu đó?
Hàm groupby cho phép bạn tổng hợp dữ liệu dựa trên một số cột cụ thể và thực hiện các phép toán trên dữ liệu được nhóm. Trong đoạn mã sau, dữ liệu được nhóm theo cột ‘Tên’ và giá trị trung bình ‘Điểm’ của mỗi nhóm được tính toán.

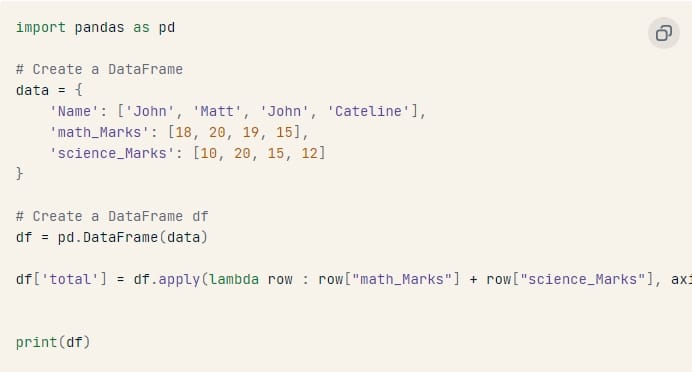
Làm thế nào bạn có thể tạo một cột mới bắt nguồn từ các cột hiện có?
Chúng ta có thể sử dụng phương thức apply() để tạo ra một cột mới bằng cách thực hiện một số phép toán trên các cột hiện có.
Đoạn mã dưới đây thêm một cột mới có tên là ‘tổng’ vào DataFrame. Cột mới này chứa tổng giá trị từ hai cột khác.
Câu hỏi phỏng vấn Pandas dành cho nhà khoa học dữ liệu
Chúng ta đã tìm hiểu tất cả các câu hỏi phỏng vấn chung và lập trình cho pandas, hãy cùng xem xét các câu hỏi phỏng vấn khoa học dữ liệu về pandas.
Bạn xử lý các giá trị null hoặc missing trong Pandas như thế nào?
Bạn có thể sử dụng bất kỳ trong ba phương pháp sau đây để xử lý các giá trị thiếu trong pandas:
- ✓ dropna() – hàm này loại bỏ các hàng hoặc cột thiếu từ DataFrame.
- ✓ fillna() – điền các giá trị null bằng một giá trị cụ thể bằng cách sử dụng hàm này.
- ✓ interpolate() – phương pháp này điền các giá trị thiếu bằng các giá trị nội suy tính toán. Kỹ thuật nội suy có thể là tuyến tính, đa thức, spline, thời gian, v.v.,
Sự khác biệt giữa phương thức fillna() và interpolate()
- ✓ fillna() – Phương pháp fillna() điền các giá trị thiếu bằng hằng số được chỉ định. Ngoài ra, bạn cũng có thể cung cấp các giá trị điền tiến hoặc điền lùi cho tham số ‘method’.
- ✓ interpolate() – Mặc định, hàm này điền các giá trị thiếu hoặc NaN bằng các giá trị nội suy tuyến tính. Tuy nhiên, bạn cũng có thể tùy chỉnh kỹ thuật nội suy thành đa thức, thời gian, chỉ số, spline, v.v., bằng cách sử dụng tham số ‘method’.
Phương pháp nội suy rất phù hợp cho dữ liệu chuỗi thời gian, trong khi fillna là một phương pháp tổng quát hơn.
Resampling là gì?
Resampling được sử dụng để thay đổi tần suất mà dữ liệu chuỗi thời gian được báo cáo. Hãy tưởng tượng bạn có dữ liệu chuỗi thời gian hàng tháng và muốn chuyển đổi nó thành dữ liệu hàng tuần hoặc hàng năm, đây chính là nơi mà resampling được sử dụng.
Chuyển đổi từ hàng tháng sang hàng tuần hoặc hàng ngày không gì khác là upsampling. Các kỹ thuật nội suy được sử dụng để tăng tần suất ở đây.
Ngược lại, việc chuyển đổi từ hàng tháng sang hàng năm được gọi là downsampling, nơi mà các kỹ thuật tổng hợp dữ liệu được áp dụng.
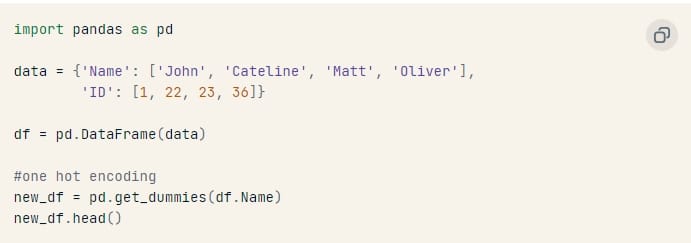
Làm thế nào để thực hiện mã hóa one-hot bằng thư viện pandas?
Chúng ta thực hiện mã hóa one hot để chuyển đổi các giá trị phân loại thành các giá trị số để có thể đưa vào thuật toán học máy.
Làm thế nào để tạo đồ thị đường trong thư viện pandas?
Để vẽ biểu đồ đường, chúng ta có một hàm plot trong pandas.

Phương thức của pandas để lấy bản tóm tắt thống kê của tất cả các cột trong DataFrame là gì?
df.describe()
Phương thức này trả về các thống kê như giá trị trung bình, giá trị phân vị, giá trị tối thiểu, tối đa, vv., của mỗi cột trong DataFrame.
Rolling có nghĩa là gì?
Rolling cũng được gọi là trung bình di động vì ý tưởng ở đây là tính trung bình các điểm dữ liệu trong một cửa sổ cụ thể và trượt cửa sổ qua toàn bộ dữ liệu. Điều này sẽ giảm những biến động và làm nổi bật các xu hướng dài hạn trong dữ liệu chuỗi thời gian.
Cú pháp: df[‘tên_cột’].rolling(window=n).mean()
Chuẩn bị cho cuộc phỏng vấn

Ngoài pandas, một vai trò công việc liên quan đến dữ liệu đòi hỏi rất nhiều kỹ năng khác. Đây là danh sách kiểm tra để thành công trong quá trình phỏng vấn tổng thể:
Hiểu yêu cầu công việc
Xem xét lại mô tả công việc và trách nhiệm và đảm bảo kỹ năng và sơ yếu lý lịch của bạn phù hợp với chúng. Ngoài ra, biết về công ty và vai trò của bạn tác động đến họ như thế nào là một điểm cộng.
Mã nguồn bằng Python
Người phỏng vấn thường kiểm tra kỹ năng Python của bạn trước khi thảo luận về thư viện Python như Pandas. Vì vậy, hãy trang bị cho bản thân kỹ năng Python mạnh mẽ.
Đối với vai trò của nhà phân tích, chủ yếu là kiến thức về ngôn ngữ Python. Nhưng nếu bạn đang ứng tuyển cho các vị trí nhà khoa học dữ liệu hoặc kỹ sư máy học, việc giải quyết các mã nguồn lập trình Python là rất quan trọng.
Dự án dữ liệu
Đảm bảo rằng bạn đã giải quyết một số vấn đề thực tế liên quan đến dữ liệu trong sơ yếu lý lịch của mình. Đối với những người có kinh nghiệm, bạn có thể nói về các dự án đã làm trong quá khứ. Nếu bạn mới bắt đầu trong lĩnh vực này, hãy thử hoàn thành một số dự án trên Kaggle.
Khái Niệm Tổng Quát
Đối với những người phân tích, câu hỏi có thể xoay quanh Excel, bảng điều khiển trực quan dữ liệu, thống kê và xác suất. Ngoài ra, người phỏng vấn có thể đàm phán chi tiết về các chủ đề machine learning và deep learning nếu bạn đang ứng tuyển cho vị trí nhà khoa học dữ liệu hoặc kỹ sư Machine Learning.
Chuẩn bị bằng cách sử dụng câu hỏi thường gặp trong phỏng vấn
Có khả năng cao bạn sẽ được hỏi ít nhất vài câu hỏi từ nhóm câu hỏi phổ biến nhất trong phỏng vấn. Vì vậy, hãy chuẩn bị từ những bảng tra cứu và các câu hỏi mô phỏng.
Thiết kế hệ thống ML
Dự kiến sẽ có các câu hỏi xoay quanh thiết kế hệ thống nếu bạn đang ứng tuyển cho các vị trí có tính kỹ thuật cao hoặc có kinh nghiệm. Hãy xem xét lại các câu hỏi thiết kế phổ biến và thực hành giải quyết các vấn đề thiết kế hệ thống ML từ đầu đến cuối.
Kết luận
Để thành công trong lĩnh vực dữ liệu, kỹ năng Python Pandas mạnh mẽ là quan trọng. Danh sách trên, bao gồm cả câu hỏi phỏng vấn lý thuyết và câu trả lời sẽ giúp bạn tỏa sáng trong phần Pandas của cuộc phỏng vấn. Đồng thời, những mẹo cuối cùng mà NativeX đã nhắc đến cũng sẽ đảm bảo rằng cuộc phỏng vấn của bạn diễn ra một cách suôn sẻ.
Tác giả: NativeX
















